Data Warehousing #2: Data Flow

This is the 2nd in series of posts on datawarehousing. To see the entire post list, click here.
Independent Data Marts
Like many others, I’ve worked in organizations which have evolved data marts like the one below:
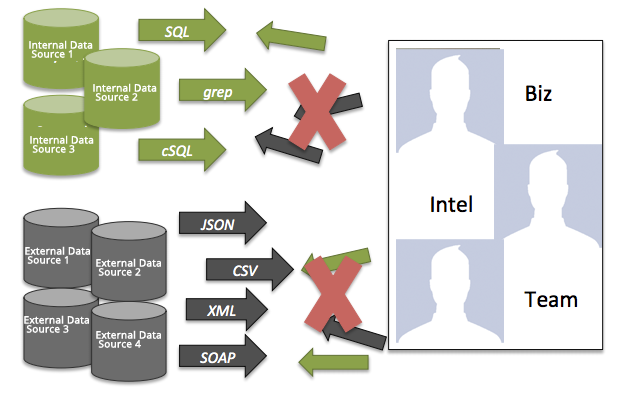
These systems are characterized by the necessity to query from multiple independent sources in order to meet a business objective. Not only is this an inefficient way of processing your data, but access to data will be out of reach of anyone who doesn’t know all of the different systems intimately! Definitions of business objects, business rules, timing, and access protocols differ from source system to source system! The only reason this data architecture is so prevalent is because is because (1) data marts align with business units, which probably align with budgets (2) a lack of upfront, cohesive design. If you are serious about making your data available, read on..
Data Warehouse Architecture
The Data Warehouse Architecture is achieved with the addition of an Extract, Transform, Load Step:
- Extract data from original data source (ODS).
- Transform the data for storing in a proper schema (more to come on schema design in an upcoming post).
- Load the data into a final target database.
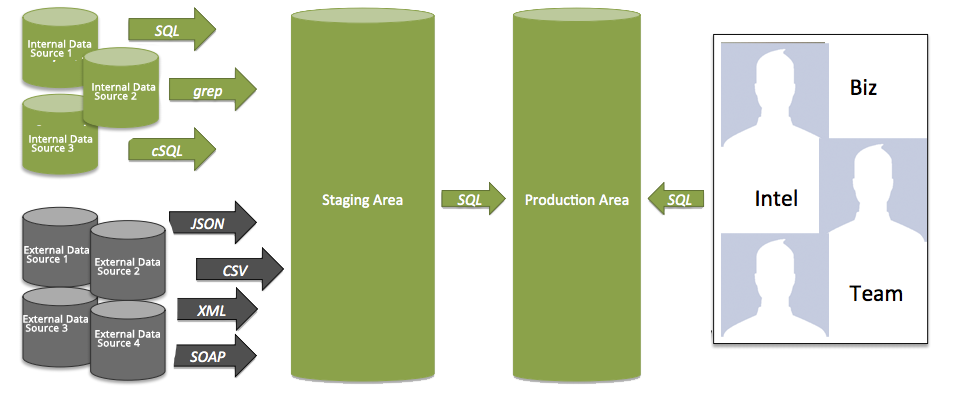
Note that a staging area exists to support the ETL of data from an operational data source. This is what we call the ‘back room’ and it is off limits to the end users.
By way of contrast, the production area is where data is presented to end users, in a conformed dimensional model. More to come on that in another post.